Java
-
HashMap, HashTable 和 ConcurrentHashMap 的区别
- HashMap是非线程安全的,HashTable 是线程安全的。
- HashMap的键和值都允许有 null 存在,而 HashTable 和 ConcurrentHashMap 都不行。
- 因为线程安全、哈希效率的问题,HashMap 效率比 HashTable 的要
- ConcurrentHashMap 对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于 HashTable 的 synchronized 关键字锁的粒度更精细了一些,并发性能更好,而 HashMap 没有锁机制,不是线程安全的。
- 三者的 hash 函数不一样
-
Java Collection
- 集合都实现了 WriteObject 与 ReadObject 用于序列化/反序列化,先写入的是集合大小,再写入的是集合元素
- ArrayList 底层是 Object[],默认大小是 10, 每次容量递增 50%,有 fail-fast 特性,常用 T[] toArray(T[] arr)
- 对于 T[] toArray(T[] arr),如果 arr.length > size 则将元素直接放入 arr,然后返回 arr,否则新造一个数组大小同 size 然后填充数组并返回
- LinkedList 底层是双向链表,且 header 不存放数据格式为 tail<->header<->first,有 fail-fast 特性,支持随机访问、链表、栈等操作
- 对于随机访问 get(int i),如果 i < size/2 则正向遍历,否则反向遍历
- pollFirst, peekFirst, offerFirst, 与 removeFirst, getLast, addFirst 等价,只是前者会返回特殊值(null或者bool),后者会抛异常
- 遍历 LinkedList 尽量使用 iterator 不要使用随机访问 get(i),后者效率极低
- Vector 是矢量队列,线程安全,底层是 Object[], 默认大小是 10,增长量可指定默认增长一倍,实现了 Enumeration 接口(JDK 1.x),有 fail-fast 特性。
- Vector本身是一个list,如果使用list来声明它,使用iterator进行迭代,此时的Vector就不是线程安全的啦。但是使用Vector的elements进行迭代就不会出现线程安全性问题
- Stack 继承与 Vector 所以是线程同步的, 只有无参构造函数
- 总结
-
Java Map
- HashMap 容量初始化 16 且以 2 倍增长,线程不安全,允许放入 null 放入的地方是 table[0],继承于 AbstractMap
- 容量按 2 倍增长的好处可以在扩容的时候方便找出对应的位置
- HashMap多线程并发问题分析 可以知道 HashMap 在 put 的时候容易引起环状链表而导致死循环
- HashTable 容量初始化 11 以 2倍+1 的方式增长,线程安全,不允许放入 null,继承于 Dictionary 和 AbstractMap
- ConcurrentHashMap源码阅读 可以知道 segment, size 计算等等
- WeakHashMap 和 HashMap 一样,区别就是如果 key 被回收了,那么 value 也会被回收
- key 是弱引用,当 key 被回收的时候,会将 key 的信息放入队列
- 在进行操作的时候首先对比队列,如果队列里面有 key 的信息则删除 key-value
- TreeMap 底层是通过红黑树实现的,支持排序,线程不安全
- 总结
- HashMap 容量初始化 16 且以 2 倍增长,线程不安全,允许放入 null 放入的地方是 table[0],继承于 AbstractMap
-
IO字节流和字符流相互转换
-
hashCode 与 equals 的区别与联系
两个 equals 不等的对象可能有相等的 hashCode。
-
Volatile的特征
- volatile是在synchronized性能低下的时候提出的。如今synchronized的效率已经大幅提升,所以volatile存在的意义不大。
- 如今非volatile的共享变量,在访问不是超级频繁的情况下,已经和volatile修饰的变量有同样的效果了。
- volatile不能保证原子性。Java并发_volatile实现可见性但不保证原子性
- volatile可以禁止重排序。
-
禁止内存重排序/内存屏障/内存栅栏
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence): 一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。(也就是让一个CPU处理单元中的内存状态对其它处理单元可见的一项技术。)
内存重排序: 在一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作。准确地说应该是控制流顺序而不是代码顺序,因为要考虑分支、循环等结构。以下规则可禁止重排序:- volatile变量规则(Volatile Variable Rule):对一个volatile变量的写操作发生于后面对这个变量的读操作,这里的“后面”也指的是时间上的先后顺序。
- 线程启动规则(Thread Start Rule):Thread独享的start()方法先行于此线程的每一个动作。
- 线程终止规则(Thread Termination Rule):线程中的每个操作都先行发生于对此线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值检测到线程已经终止执行。
- 线程中断规则(Thread Interruption Rule):对线程interrupte()方法的调用优先于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否已中断。
- 对象终结原则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
- 传递性(Transitivity):如果操作A先行发生于操作B,操作B先行发生于操作C,那就可以得出操作A先行发生于操作C的结论
-
重载与重写的区别
- 重载(Overload)指的是同一个类里面的两个方法具有相同的名称,但是方法参数类型可能不同
- 重写(Override)指的是子类覆盖父类的方法,两个方法属于不同类但是具有相同的签名
-
自动装/拆箱
- 自动装箱时编译器调用valueOf将原始类型值转换成对象,同时自动拆箱时,编译器通过调用类似intValue(),doubleValue()这类的方法将对象转换成原始类型值。
- 自动装箱是将boolean值转换成Boolean对象,byte值转换成Byte对象,char转换成Character对象,float值转换成Float对象,int转换成Integer,long转换成Long,short转换成Short,自动拆箱则是相反的操作。
-
基本类型
byte(8)、short(8)、int(32)、long(64)、float(32)、double(64)、boolean(1)、char(8) 8种
-
线程
- Java 线程与 Os 线程是 1:1 中间并没有什么优化,底层是 pThread 实现的o
- Java 可以通过 taskset 实现线程与 Cpu 绑定
-
静态代理、动态代理
-
过滤器与拦截器
-
Serializable 接口详解
-
实现多线程的方式
-
进程的三态转换
-
String, StringBuffer, StringBuilder 的区别
- String字符串是常量,其值不能改变
- StringBuilder是线程不安全的,速度更快
- StringBuffer是线程安全的,速度比StringBuilder慢
- Java 中 String、StringBuffer和StringBuilder的区别
-
Java和C/C++之间的差别
-
Java 的编译过程
- 词法分析,标记最小元素比如:变量名,类型,操作符,字面量、修饰符等等
- 语法分析,将词法分析的结果生成一颗语法树
- 语义分析,确保语法树的所有节点正确,变量使用前是否声明、赋值、类型是否匹配、方法是否有返回值等等
- 生成中间字节码,该字节码与平台无关,仅仅将上述步骤的结果写入磁盘
- JIT 编译,如果某个 方法/循环体 执行频率比较高,则会在字节码解释过程中将高频率字节码编译成机器码,这样就不用每次都解释这些代码。
- 判断高频率代码的两种方法:
- 基于采样的热点探测:周期扫描每个线程栈的栈顶,如果某段字节码出现频率比较高,则认为是「热点代码」
该方法虽然简单,但是无法排除因为线程阻塞等因素而干扰判断结果
- 基于计数器的热点探测:为每个方法,甚至代码块添加计数器,如果计数超过一定的阈值则任务是「热点代码」
该方法检测准确,实现难度较高
- HotStop 等虚拟机采用的是第二种「基于计数器的热点探测」,有两个计数器:方法调用计数器和回边计数器。一个统计方法调用次数,一个统计循环体调用次数
Web
-
Session, Cookie的区别
-
sendRedirect, foward的区别
Jvm
SQL
-
数据库事务隔离机制的特点
-
数据库优化查询
-
三范式
System
-
在Linux上,对于多进程,子进程继承了父进程的哪些
- 子进程继承父进程
用户号UIDs和用户组号GIDs、环境Environment、堆栈、共享内存、打开文件的描述符、执行时关闭(Close-on-exec)标志、信号(Signal)控制设定、进程组号、当前工作目录、根目录、文件方式创建屏蔽字、资源限制、控制终端 - 子进程独有
进程号PID、不同的父进程号、自己的文件描述符和目录流的拷贝、子进程不继承父进程的进程正文(text),数据和其他锁定内存(memory locks)、不继承异步输入和输出 - 父进程和子进程拥有独立的地址空间和PID参数
- 子进程继承父进程
-
TCP 的三次、四次握手
-
文件系统管理的最小磁盘空间单位是
微软操作系统(DOS、WINDOWS等)中磁盘文件存储管理的最小单位叫做「簇」
扇区:硬盘不是一次读写一个字节而是一次读写一个扇区(512个字节)
簇:系统读读写文件的基本单位,一般为2的n次方个扇区(由文件系统决定)块可以包含若干页,页可以包含若干簇,簇可以包含若干扇区 块–>页–>簇–>扇区
-
poll, select 和 epoll 区别
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现。
- 支持一个进程所能打开的最大连接数
select
依赖于宏 FD_SETSIZE(x86 上面为 3232,x64 上面为 3264)
poll
无限制,原因是基于链表结构来存储的
epoll
有上限,但是很大,1G 内存大概为 10万,2G 内存大概为 20万 - FD 剧增后带来的 IO 效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的「线性下降性能问题」。
poll
同上,有「线性下降性能问题」
epoll
epoll 根据每个 fd 的「callback」来实现的,只有活跃的 socket 才能调用 callback,所以没有「线性下降性能问题」 - 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
通过内核和用户空间共享一块内存来实现的 - 总结
- 在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
- select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
- 支持一个进程所能打开的最大连接数
-
伪共享
-
冯洛伊曼体系结构
计算机的数制采用二进制;计算机应该按照程序顺序执行
-
信息熵
通俗的理解就是,信息储存在计算机上的最小空间
-
栈溢出攻击
-
程序运行栈的结构
栈帧:局部变量、操作数、动态链接库、返回地址(从上到下),地址是从高到底进行增长
-
用户线程和内核线程
-
正向代理和反向代理
正向代理:客户端–>服务器,反向代理:服务器–>客户端
-
Netty 百万连接优化
-
进程线程通信
- Linux进程间通信:管道、信号、消息队列、共享内存、信号量、套接字(socket)
- Linux线程间通信:互斥量(mutex),信号量,条件变量
- Windows进程间通信:管道、消息队列、共享内存、信号量 (semaphore) 、套接字(socket)
- Windows线程间通信:互斥量(mutex),信号量(semaphore)、临界区(critical section)、事件(event)
Personal
-
Mq 的原理
- 流程 (Publisher)
- 第一:获取Conection
- 第二:获取Channel
- 第三:定义Exchange,Queue
- 第四:使用一个RoutingKey将Queue Binding到一个Exchange上
- 第五:通过指定一个Exchange和一个RoutingKey来将消息发送到对应的Queue上,
- 第六:Consumer在接收时也是获取connection,接着获取channel,然后指定一个Queue,到Queue上取消息,它对Exchange,RoutingKey及如何Binding都不关心,到对应的Queue上去取消息就行了。
-
Spring AOP
- JDK 代理:通过反射实现一个代理类,只能代理接口,如果接口没函数则抛错
- CGLib:通过 ASM 框架实现一个代理类,通过继承被代理的类,所以只能代理非
final/static/private的方法,不能代理final的类 - AspectJ: 使用的是静态代理,即在编译阶段就生成了代理类,所以可代理类的所有方法只要加上注解就行包括
private/static/final都可以代理 - Spring AOP:动态代理,自动选择 JDK 代理 和 CGLib 代理,同时也引入了 AspectJ 的一些注解
- JDK 代理默认代理了对象的
equals/toString, CGLib 还代理了clone/finalize等方法
-
Spring IOC
- 读取 Bean 的配置信息可以是 xml 或者注解
- 将 Bean 的信息注册的一张全局表里面
- 在调用
getBean的时候才会从全局表里面根据依赖关系实例化 Bean,期间会回调 Bean 上注册的方法 (比如:init-method),以及容器本身的回调方法 - 如果 Bean 的
scop设置的时候单例,那么就会将实例化后的 Bean 放入全局的缓存池 (HashMap) - 对于单例的 Bean 在容器销毁的时候会回调 Bean 的回调方法
destory-method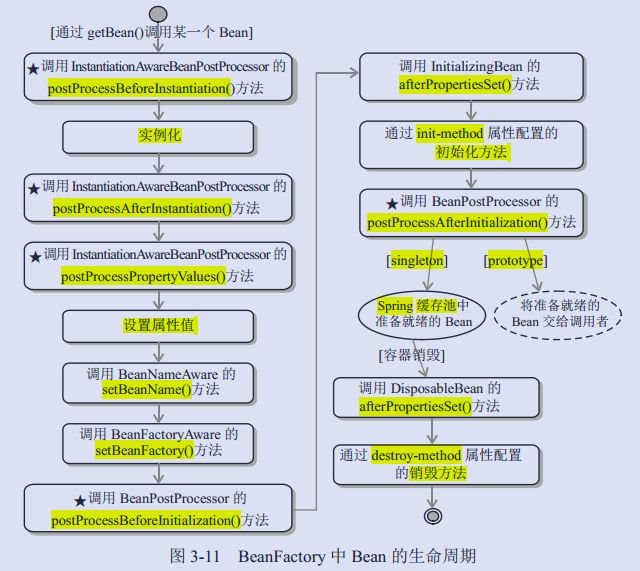
-
InfluxDb
-
Redis
深入浅出Redis-redis底层数据结构(上)
深入浅出Redis-redis底层数据结构(下)
Redis的那些最常见面试问题- Redis 底层有 SDS(字符串)、双向无环链表、跳跃表、压缩列表、Hash字典、整数等数据结构
Algorithm
1. 已知一棵二叉树的前序遍历为CABEFDHG,中序遍历为BAFECHDG,那么它的后续遍历是:
这类由二叉树的(前序遍历+中序遍历 ==> 后序遍历)或者(后续遍历 + 中序遍历 ==> 前序遍历)的解法如下:
- 找到树的根节点,前序遍历的第一个节点,后续遍历的最后一个节点
- 中序遍历中根节点左边的为左子树,根节点右边的为又子树
- 在前序/后序遍历中找到左右子树的根节点,在中序遍历中找到,子树的左右子树
- 通过上面的递归处理,就能复原二叉树,最后根据复原的二叉树进行遍历即可
以本题为例: 前序遍历:CABEFDHG 中序遍历:BAFECHDG
- 找到根节点 C,左子树:ABEF/BAFE,右子树:DHG/HDG
注:ABEF/BAFE 表示前序遍历:ABEF,中序遍历:BAFE
graph TD C --> L[ABEF/BAFE] C --> R[DHG/HDG] -
左子树 ABEF/BAFE 的根节点:A,左子树:B,右子树:EF/FE
graph TD A --> L[B] A --> R[EF/FE] -
左子树 B,右子树:EF/FE(F 是E的左子树),所以整个左子树如下:
graph TD C --> A A --> B A --> E E --> NULL E --> F -
同理,还原整个二叉树如下:
graph TD C --> A A --> B A --> E E --> NULL E --> F C --> D D --> H D --> G - 所以后续遍历为:BFEAHGDC
Summary
- C/C++ 各个类型在 x86/x64 的长度
详见:C 类型长度
- C/C++ 的 struct 所占的字节数(字节对齐)
详见:C 字节对齐
- C++ 的 class 的多态数原理、析构函数调用顺序等
- 二叉树的各项遍历,以及根据(前、中)推后续遍历,根据(后、中)推前序遍历
详见:本文的 Algorithm 部分
- 具有 n 个几点二叉树的形态个数公式 \[C_{2n} ^ n \over (n+1) \]
- 二叉树度为 0 的点比度为 2 的点多 1 个
- 设树有 \(n\) 个节点,则有 \(n-1\) 条边
- 则 \(2n_2 + n_1 = n-1\)(2 度节点有两条边,1 度节点只有一条边)
- 而 \(n_2 + n_1 + n_0 = n\),所以 \(n_0 = n_2 +1\)
- SQL中 count(*) 跟 count(1) 的结果一样,都包括对NULL的统计,而count(column) 是不包括NULL的统计
- 树的度与节点的关系
\[2*n_2 + 1*n_1 + n_0 = n_2 + n_1 + n_0\]度的和 = 节点数和 - 1 完全二叉树 \(n_0 = n_1+1 或者 n_0 = n_1\)
- P2P 通信,每次只有两个点通信,要使每个节点知道网络全部信息的通信次数,\(N\)为节点个数 \[2N-4\]
- 排列组合的捆绑法、插空法、插板法。
- 括弧()排列算法,假设()的对数为 \(N\) \[C_{2n} ^ n \over (N+1) \]
- 选择排列之和
C(0,n)+C(1,n)+C(2,n)+…+C(n-1,n)+C(n,n) =2^n