邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。kNN 算法是一个分类算法,通过判断待测试样本与训练样本的距离来确定测试样本的类别。
准备
本文的样例和代码均来自于《机器学习实战》
给定样本
| 序号 | 特征1 | 特征2 | 特征3 | 分类 |
|---|---|---|---|---|
| 1 | 0.8 | 400 | 0.5 | 1 |
| 2 | 12 | 134000 | 0.9 | 3 |
| 3 | 0 | 20000 | 1.1 | 2 |
| 4 | 67 | 32000 | 0.1 | 2 |
欧氏距离
\(N\) 维欧氏空间中两点 \((x_1,x_2)\) 两点的距离公式
\[\sqrt{\sum_{i=1}^{N}({x_1 - x_2})^2}\]当 \(N=2\) 时,欧式距离即为标准差:
\[\sqrt{({x_1 - x_2})^2}\]比如 样本3 和 样本4 之间的欧氏距离:
\[\sqrt{(0 - 67)^2 + (20000 - 32000)^2 +(1.1 - 0.1)^2}\]数据归一化
由于样本的某些特征值数据范围过大(比如示例中的特征2)其对欧式距离的影响将会特别大,所以要将其归一化,数据归一的化的原理是将样本中的所有特征值的数据都变成 \([0,1]\) 范围内的数据,即
\[\acute{x_i} = \frac{x_i - min_i}{max_i - min_i}\]其中 \(x_i\) 为样本 \(x\) 的第 \(i\) 个特征值,\(min_i\) 为所有样本中第 \(i\) 个特征值中的最小值,\(max_i\) 为样本中第 \(i\) 个特征值的最大值
算法思想
- 将特征数据归一化
- 计算测试数据与训练的每一个样本数据的距离
- 将距离有小到大排序取出前 k 个对应的样本数据
- 统计这 k 个样本里面频率最高的分类信息,该分类就是测试数据的分类
算法实现
数据归一化
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normSet = dataSet - tile(minVals,(m,1))
normSet = normSet / tile(ranges,(m,1))
return normSet,ranges,minVals
kNN 实现
# intX 为待测试的样本
# dataSet 是归一化之后的数据
# labels 为 dataSet 每一行的分类信息
# k 要取得小距离样本的个数
def classify0(intX,dataSet,labels,k):
# 行数量
size = dataSet.shape[0]
# 样本 intX,重复 size 行 形成一个与 dataSet 维数一样的矩阵,然后做差
diffMat = tile(intX,(size,1)) - dataSet
# 每个差值取平方
sqDiffMat = diffMat ** 2
# aixs=1 表明对差方矩阵的行求和
# 一行数据变成 1 个,相当于算出输入样本和训练样本每行的距离
sqDistance = sqDiffMat.sum(axis=1)
distance = sqDistance ** 0.5
# argSort 返回的是索引,其对应的值从小到大
sortIndicies = distance.argsort()
classCount = {}
# 取出前 k 个小距离对应的标签
for i in range(k):
voteLabel = labels[sortIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel,0) +1
# 取出所有标签中频率最高的标签
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
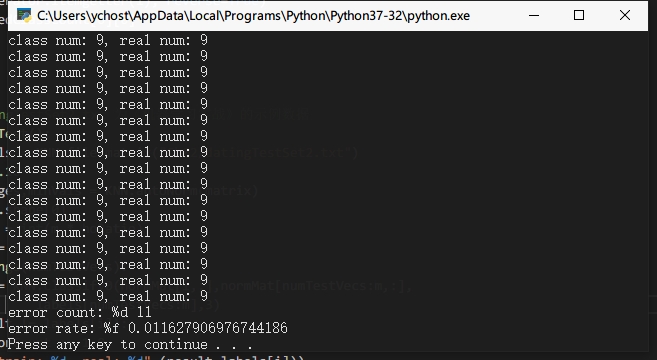
测试算法
# 注:用到的datingTestSet2.txt 为《机器学习实战》的示例数据
def datingClassTest():
matrix,labels = KNN.file2matrix("Ch02/datingTestSet2.txt")
hoRatio = 0.10
normMat,ranges,minVals = KNN.autoNorm(matrix)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0
for i in range(numTestVecs):
result = KNN.classify0(normMat[i,:],normMat[numTestVecs:m,:],
labels[numTestVecs:m],3)
if(result != labels[i]):
errorCount += 1.0
print("train: %d, real: %d",(result,labels[i]))
print("error count: %f",errorCount / float(numTestVecs))
return